Introduction
Background
With the rapid advancement of artificial intelligence and machine learning (AI/ML), researchers from a wide range of disciplines increasingly use predictions from pre-trained algorithms as outcome variables in statistical analyses. However, reifying algorithmically-derived values as measured outcomes may lead to biased estimates and anti-conservative inference (Salerno et al., 2025). The statistical challenges encountered when drawing inference on predicted data (IPD) include:
- Understanding the relationship between predicted outcomes and their true, unobserved counterparts
- Quantifying the robustness of the AI/ML models to resampling or uncertainty about the training data
- Appropriately propagating both bias and uncertainty from predictions into downstream inferential tasks
Several works have proposed methods for IPD, including
post-prediction inference (PostPI) by Wang et al., 2020,
prediction-powered inference (PPI) and PPI++ by Angelopoulos et al.,
2023a and Angelopoulos et al.,
2023b, post-prediction adaptive inference (PSPA) by Miao et al., 2023,
and a correction based on the Chen and Chen method and alternate PPI
“All” by Gronsbell
et al., 2025. To enable researchers and practitioners interested in
these state-of-the-art methods, we have developed ipd, a
open-source R package that implements these methods under
the umbrella of IPD.
This vignette provides a guide to using the ipd package,
including installation instructions, examples of data generation, model
fitting, and usage of custom methods. The examples demonstrate the
package’s functionality.
Notation
Following the notation of Miao et al., 2023, we assume we have the following data structure:
- Labeled data ; unlabeled data .
- The labeled set is typically smaller in size compared to the unlabeled set.
- We have access to an algorithm that can predict our outcome, .
- Our interest is in performing inference on a quantity such as the outcome mean or quantile, or to recover a downstream inferential (mean) model:
where is a vector of regression coefficients and is a given link function, such as the identity link for linear regression, the logistic link for logistic regression, or the log link for Poisson regression. However, in practice, we do not observe in the ‘unlabeled’ subset of the data. Instead, these values are replaced by the predicted . We can use methods for IPD to obtain corrected estimates and standard errors when we replace these unobserved by .
Installation
To install the ipd package from Bioconductor, you can use the
BiocManager package:
#-- Install BiocManager if it is not already installed
if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(version = "3.21")
#-- Install the ipd package from Bioconductor
BiocManager::install("ipd")Or, to install the development version of ipd from GitHub, you can use the
devtools package:
#-- Install devtools if it is not already installed
install.packages("devtools")
#-- Install the ipd package from GitHub
devtools::install_github("ipd-tools/ipd")Usage
We provide a simple example to demonstrate the basic use of the
functions included in the ipd package.
Data Generation
The ipd packages provides a unified function,
simdat, for generating synthetic datasets for various
models. The function currently supports “mean”, “quantile”, “ols”,
“logistic”, and “poisson” models.
Function Arguments
-
n: A vector of size 3 indicating the sample size in the training, labeled, and unlabeled data sets. -
effect: A float specifying the regression coefficient for the first variable of interest (defaults to 1). -
sigma_Y: A float specifying the residual variance for the generated outcome. -
model: The type of model to be generated. Must be one of"mean","quantile","ols","logistic", or"poisson".
The simdat function generate a data.frame with three
subsets: (1) an independent “training” set with additional observations
used to fit a prediction model, and “labeled” and “unlabeled” sets which
contain the observed and predicted outcomes and the simulated features
of interest.
Generating Data for Linear Regression
We can generate a continuous outcome and relevant predictors for
linear regression as follows. The simdat function generates
four independent covariates,
,
,
,
and
,
and the outcome:
where effect is one of the function arguments and
,
with sigma_Y being another argument. Here, the
simdat function generates three subsets of data, a
“training” subset, a “labeled” subset, and an “unlabeled” subset, based
on the sizes in n. It then learns the prediction rule for
the outcome in the “training” subset using a generalized additive model
and predicts these outcomes in the “labeled” and “unlabeled”
subsets:
#-- Generate a Dataset for Linear Regression
set.seed(123)
n <- c(10000, 500, 1000)
dat_ols <- simdat(n = n, effect = 1, sigma_Y = 4, model = "ols",
shift = 1, scale = 2)
#-- Print First 6 Rows of Training, Labeled, and Unlabeled Subsets
options(digits = 2)
head(dat_ols[dat_ols$set_label == "training", ])
#> X1 X2 X3 X4 Y f set_label
#> 1 -0.560 -0.56 0.82 -0.356 -0.15 NA training
#> 2 -0.230 0.13 -1.54 0.040 -4.49 NA training
#> 3 1.559 1.82 -0.59 1.152 -1.08 NA training
#> 4 0.071 0.16 -0.18 1.485 -3.67 NA training
#> 5 0.129 -0.72 -0.71 0.634 2.19 NA training
#> 6 1.715 0.58 -0.54 -0.037 -1.42 NA training
head(dat_ols[dat_ols$set_label == "labeled", ])
#> X1 X2 X3 X4 Y f set_label
#> 10001 2.37 -1.8984 0.20 -0.17 1.40 1.120 labeled
#> 10002 -0.17 1.7428 0.26 -2.05 3.56 0.017 labeled
#> 10003 0.93 -1.0947 0.76 1.25 -3.66 0.686 labeled
#> 10004 -0.57 0.1757 0.32 0.65 -0.56 -0.212 labeled
#> 10005 0.23 2.0620 -1.35 1.46 -0.82 -0.573 labeled
#> 10006 1.13 -0.0028 0.23 -0.24 7.30 0.579 labeled
head(dat_ols[dat_ols$set_label == "unlabeled", ])
#> X1 X2 X3 X4 Y f set_label
#> 10501 0.99 -3.280 -0.39 0.97 8.4 0.124 unlabeled
#> 10502 -0.66 0.142 -1.36 -0.22 -7.2 -1.040 unlabeled
#> 10503 0.58 -1.368 -1.73 0.15 5.6 -0.653 unlabeled
#> 10504 -0.14 -0.728 0.26 -0.23 -4.2 -0.047 unlabeled
#> 10505 -0.17 -0.068 -1.10 0.58 2.2 -0.693 unlabeled
#> 10506 0.58 0.514 -0.69 0.97 -1.2 -0.122 unlabeledThe simdat function provides observed and unobserved
outcomes for both the labeled and unlabeled datasets, though in practice
the observed outcomes are not in the unlabeled set. We can visualize the
relationships between these variables in the labeled data subset:
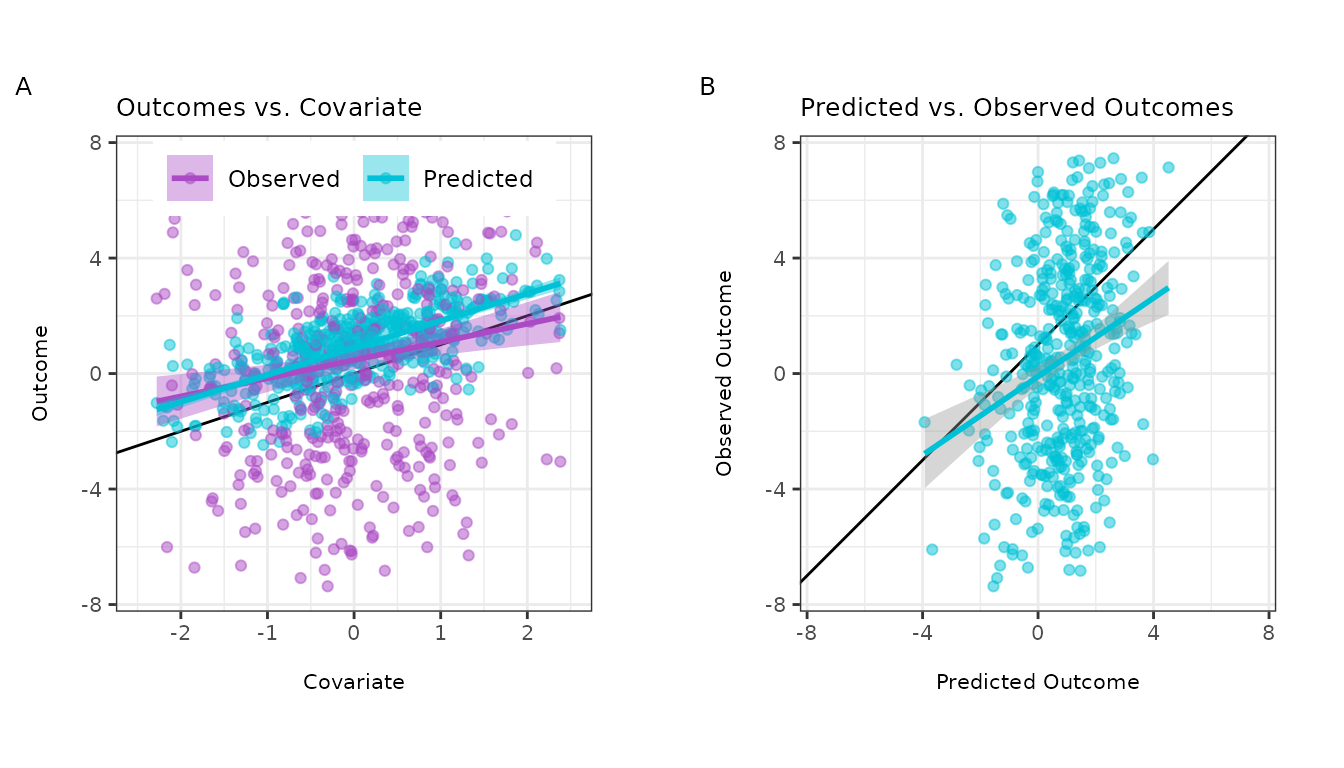
We can see that:
- The predicted outcomes are more correlated with the covariate than the true outcomes (panels A and B).
- The predicted outcomes are not perfect substitutes for the true outcomes (panel C).
Generating Data for Logistic Regression
As another example, we can generate a binary outcome and relevant predictors for logistic regression as follows:
#-- Generate a Dataset for Logistic Regression
set.seed(123)
dat_logistic <- simdat(n = n, effect = 3, sigma_Y = 1, model = "logistic")
#-- Print First 6 Rows of Training, Labeled, and Unlabeled Subsets
head(dat_logistic[dat_logistic$set_label == "training", ])
#> X1 X2 X3 X4 Y f set_label
#> 1 -0.560 -0.56 0.82 -0.356 1 NA training
#> 2 -0.230 0.13 -1.54 0.040 0 NA training
#> 3 1.559 1.82 -0.59 1.152 1 NA training
#> 4 0.071 0.16 -0.18 1.485 0 NA training
#> 5 0.129 -0.72 -0.71 0.634 0 NA training
#> 6 1.715 0.58 -0.54 -0.037 1 NA training
head(dat_logistic[dat_logistic$set_label == "labeled", ])
#> X1 X2 X3 X4 Y f set_label
#> 10001 2.37 -1.8984 0.20 -0.17 1 1 labeled
#> 10002 -0.17 1.7428 0.26 -2.05 1 1 labeled
#> 10003 0.93 -1.0947 0.76 1.25 1 1 labeled
#> 10004 -0.57 0.1757 0.32 0.65 1 0 labeled
#> 10005 0.23 2.0620 -1.35 1.46 1 1 labeled
#> 10006 1.13 -0.0028 0.23 -0.24 1 1 labeled
head(dat_logistic[dat_logistic$set_label == "unlabeled", ])
#> X1 X2 X3 X4 Y f set_label
#> 10501 0.99 -3.280 -0.39 0.97 1 1 unlabeled
#> 10502 -0.66 0.142 -1.36 -0.22 0 0 unlabeled
#> 10503 0.58 -1.368 -1.73 0.15 1 1 unlabeled
#> 10504 -0.14 -0.728 0.26 -0.23 0 0 unlabeled
#> 10505 -0.17 -0.068 -1.10 0.58 1 0 unlabeled
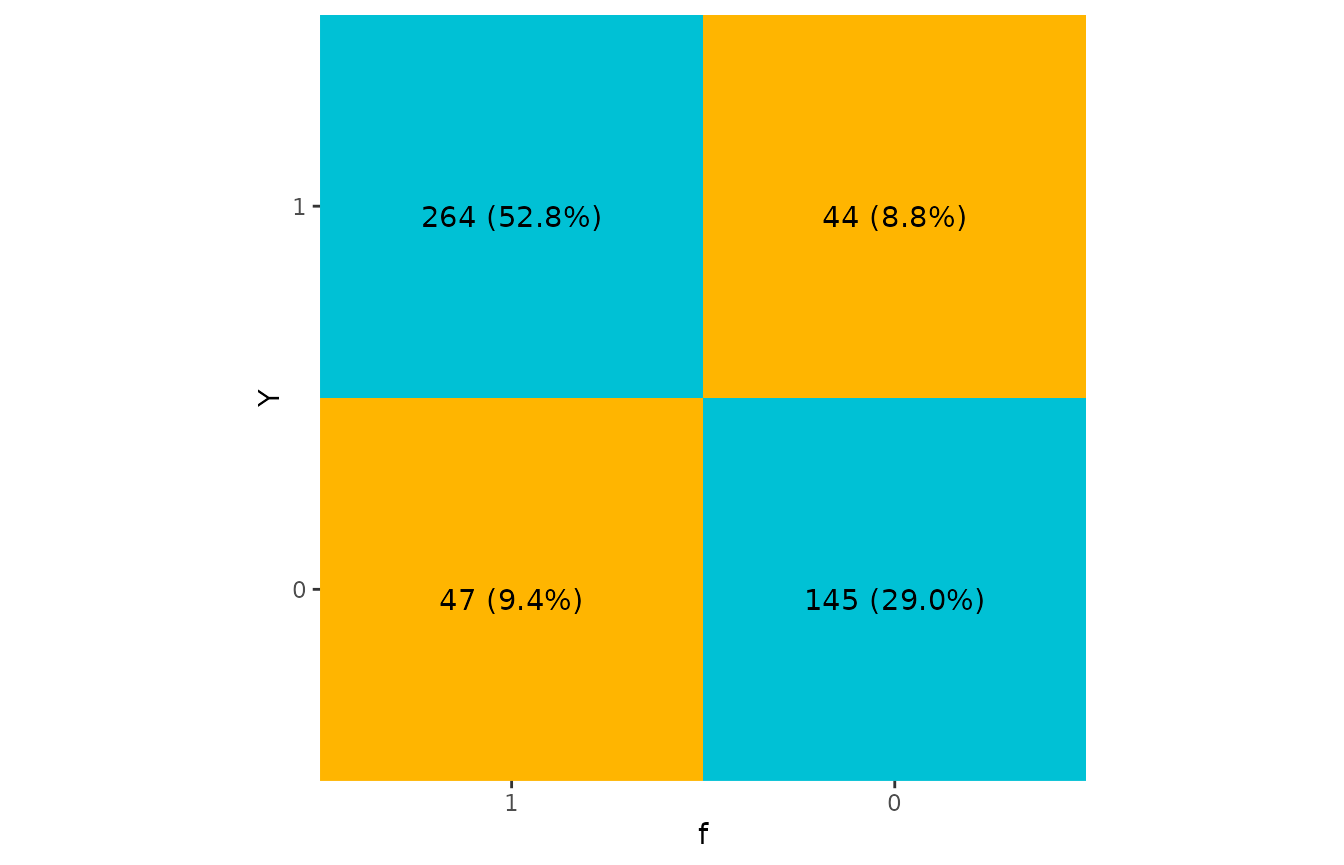
#> 10506 0.58 0.514 -0.69 0.97 1 1 unlabeledWe can again visualize the relationships between the true and predicted outcome variables in the labeled data subset and see that 81.8% observations are correctly predicted:
Model Fitting
Linear Regression
We compare two non-IPD approaches to analyzing the data to methods
included in the ipd package. The two non-IPD benchmarks are
the ‘naive’ method and the ‘classic’ method. The ‘naive’ treats the
predicted outcomes as if they were observed and regresses the
predictions on the covariates of interest without calibration. The
‘classic’ uses only the subset of labeled observations where we observe
the true outcome. The IPD methods are listed in alphabetical order by
method name.
‘Naive’ Regression Using the Predicted Outcomes
#--- Fit the Naive Regression
lm(f ~ X1, data = dat_ols[dat_ols$set_label == "unlabeled", ]) |>
summary()
#>
#> Call:
#> lm(formula = f ~ X1, data = dat_ols[dat_ols$set_label == "unlabeled",
#> ])
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.2713 -0.3069 -0.0076 0.3173 1.4453
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.0805 0.0148 -5.42 7.4e-08 ***
#> X1 0.4924 0.0148 33.32 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.47 on 998 degrees of freedom
#> Multiple R-squared: 0.527, Adjusted R-squared: 0.526
#> F-statistic: 1.11e+03 on 1 and 998 DF, p-value: <2e-16‘Classic’ Regression Using only the Labeled Data
#--- Fit the Classic Regression
lm(Y ~ X1, data = dat_ols[dat_ols$set_label == "labeled", ]) |>
summary()
#>
#> Call:
#> lm(formula = Y ~ X1, data = dat_ols[dat_ols$set_label == "labeled",
#> ])
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -15.262 -2.828 -0.094 2.821 11.685
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.908 0.187 4.86 1.6e-06 ***
#> X1 1.097 0.192 5.71 1.9e-08 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 4.2 on 498 degrees of freedom
#> Multiple R-squared: 0.0614, Adjusted R-squared: 0.0596
#> F-statistic: 32.6 on 1 and 498 DF, p-value: 1.95e-08You can fit the various IPD methods to your data and obtain summaries
using the provided wrapper function, ipd():
Chen and Chen Correction (Gronsbell et al., 2025)
#-- Specify the Formula
formula <- Y - f ~ X1
#-- Fit the Chen and Chen Correction
ipd::ipd(formula, method = "chen", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: chen
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.880 0.182 4.83 1.4e-06 ***
#> X1 1.115 0.195 5.72 1.0e-08 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Prediction Decorrelated Inference (Gan et al., 2024)
#-- Fit the PDC Correction
ipd::ipd(formula, method = "pdc", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: pdc
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.902 0.185 4.87 1.1e-06 ***
#> X1 1.097 0.198 5.53 3.2e-08 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1PostPI Bootstrap Correction (Wang et al., 2020)
#-- Fit the PostPI Bootstrap Correction
nboot <- 200
ipd::ipd(formula, method = "postpi_boot", model = "ols",
data = dat_ols, label = "set_label", nboot = nboot) |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: postpi_boot
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.873 0.183 4.77 1.9e-06 ***
#> X1 1.151 0.183 6.30 2.9e-10 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1PostPI Analytic Correction (Wang et al., 2020)
#-- Fit the PostPI Analytic Correction
ipd::ipd(formula, method = "postpi_analytic", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: postpi_analytic
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) -0.187 0.187 -1.00 0.32
#> X1 1.128 0.191 5.92 3.3e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Prediction-Powered Inference (PPI; Angelopoulos et al., 2023)
#-- Fit the PPI Correction
ipd::ipd(formula, method = "ppi", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: ppi
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.890 0.183 4.87 1.1e-06 ***
#> X1 1.110 0.195 5.69 1.3e-08 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1PPI “All” (Gronsbell et al., 2025)
#-- Fit the PPI Correction
ipd::ipd(formula, method = "ppi_a", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: ppi_a
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.896 0.183 4.91 9.2e-07 ***
#> X1 1.106 0.195 5.67 1.4e-08 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1PPI++ (Angelopoulos et al., 2023)
#-- Fit the PPI++ Correction
ipd::ipd(formula, method = "ppi_plusplus", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: ppi_plusplus
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.904 0.185 4.87 1.1e-06 ***
#> X1 1.100 0.190 5.78 7.5e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Post-Prediction Adaptive Inference (PSPA; Miao et al., 2023)
#-- Fit the PSPA Correction
ipd::ipd(formula, method = "pspa", model = "ols",
data = dat_ols, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: pspa
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.900 0.185 4.87 1.1e-06 ***
#> X1 1.095 0.190 5.76 8.5e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Logistic Regression
We also show how these methods compare for logistic regression.
‘Naive’ Regression Using the Predicted Outcomes
#--- Fit the Naive Regression
glm(f ~ X1, family = binomial,
data = dat_logistic[dat_logistic$set_label == "unlabeled", ]) |>
summary()
#>
#> Call:
#> glm(formula = f ~ X1, family = binomial, data = dat_logistic[dat_logistic$set_label ==
#> "unlabeled", ])
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.173 0.125 9.36 <2e-16 ***
#> X1 3.832 0.257 14.93 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for binomial family taken to be 1)
#>
#> Null deviance: 1328.13 on 999 degrees of freedom
#> Residual deviance: 569.36 on 998 degrees of freedom
#> AIC: 573.4
#>
#> Number of Fisher Scoring iterations: 7‘Classic’ Regression Using only the Labeled Data
#--- Fit the Classic Regression
glm(Y ~ X1, family = binomial,
data = dat_logistic[dat_logistic$set_label == "labeled", ]) |>
summary()
#>
#> Call:
#> glm(formula = Y ~ X1, family = binomial, data = dat_logistic[dat_logistic$set_label ==
#> "labeled", ])
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.677 0.121 5.58 2.5e-08 ***
#> X1 2.064 0.196 10.56 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for binomial family taken to be 1)
#>
#> Null deviance: 665.99 on 499 degrees of freedom
#> Residual deviance: 449.44 on 498 degrees of freedom
#> AIC: 453.4
#>
#> Number of Fisher Scoring iterations: 5You can again fit the various IPD methods to your data and obtain
summaries using the provided wrapper function, ipd():
PostPI Bootstrap Correction (Wang et al., 2020)
#-- Specify the Formula
formula <- Y - f ~ X1
#-- Fit the PostPI Bootstrap Correction
nboot <- 200
ipd::ipd(formula, method = "postpi_boot", model = "logistic",
data = dat_logistic, label = "set_label", nboot = nboot) |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: postpi_boot
#> Model: logistic
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.5503 0.0741 7.43 1.1e-13 ***
#> X1 1.1252 0.0891 12.63 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Prediction-Powered Inference (PPI; Angelopoulos et al., 2023)
#-- Fit the PPI Correction
ipd::ipd(formula, method = "ppi", model = "logistic",
data = dat_logistic, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: ppi
#> Model: logistic
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.711 0.162 4.39 1.1e-05 ***
#> X1 2.092 0.214 9.79 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1PPI++ (Angelopoulos et al., 2023)
#-- Fit the PPI++ Correction
ipd::ipd(formula, method = "ppi_plusplus", model = "logistic",
data = dat_logistic, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: ppi_plusplus
#> Model: logistic
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.688 0.128 5.39 7.1e-08 ***
#> X1 2.074 0.189 10.95 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Post-Prediction Adaptive Inference (PSPA; Miao et al., 2023)
#-- Fit the PSPA Correction
ipd::ipd(formula, method = "pspa", model = "logistic",
data = dat_logistic, label = "set_label") |>
summary()
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: pspa
#> Model: logistic
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.684 0.124 5.52 3.4e-08 ***
#> X1 2.072 0.192 10.77 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Printing, Summarizing, and Tidying
The package also provides custom print,
summary, tidy, glance, and
augment methods to facilitate easy model inspection:
#-- Fit the PostPI Bootstrap Correction
nboot <- 200
fit_postpi <- ipd::ipd(formula, method = "postpi_boot", model = "ols",
data = dat_ols, label = "set_label", nboot = nboot)Print Method
The print method gives an abbreviated summary of the
output from the ipd function:
#-- Print the Model
print(fit_postpi)
#> IPD inference summary
#> Method: postpi_boot
#> Model: ols
#> Formula: Y - f ~ X1
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.867 0.183 4.73 2.2e-06 ***
#> X1 1.154 0.183 6.32 2.6e-10 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Summary Method
The summary method gives more detailed information about
the estimated coefficients, standard errors, and confidence limits:
#-- Summarize the Model
summ_fit_postpi <- summary(fit_postpi)
#-- Print the Model Summary
print(summ_fit_postpi)
#>
#> Call:
#> Y - f ~ X1
#>
#> Method: postpi_boot
#> Model: ols
#> Intercept: Yes
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.867 0.183 4.73 2.2e-06 ***
#> X1 1.154 0.183 6.32 2.6e-10 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Tidy Method
The tidy method organizes the model coefficients into a
tidy format.
#-- Tidy the Model Output
tidy(fit_postpi)
#> # A tibble: 2 × 5
#> term estimate std.error conf.low conf.high
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.867 0.183 0.508 1.23
#> 2 X1 1.15 0.183 0.796 1.51Glance Method
The glance method returns a one-row summary of the model
fit.
#-- Get a One-Row Summary of the Model
glance(fit_postpi)
#> # A tibble: 1 × 6
#> method model intercept nobs_labeled nobs_unlabeled call
#> <chr> <chr> <lgl> <int> <int> <chr>
#> 1 postpi_boot ols TRUE 500 1000 Y - f ~ X1Augment Method
The augment method adds model predictions and residuals
to the original dataset.
#-- Augment the Original Data with Fitted Values and Residuals
augmented_df <- augment(fit_postpi)
head(augmented_df)
#> X1 X2 X3 X4 Y f set_label .fitted .resid
#> 10501 0.99 -3.280 -0.39 0.97 8.4 0.124 unlabeled 2.00 6.4
#> 10502 -0.66 0.142 -1.36 -0.22 -7.2 -1.040 unlabeled 0.10 -7.3
#> 10503 0.58 -1.368 -1.73 0.15 5.6 -0.653 unlabeled 1.53 4.1
#> 10504 -0.14 -0.728 0.26 -0.23 -4.2 -0.047 unlabeled 0.71 -4.9
#> 10505 -0.17 -0.068 -1.10 0.58 2.2 -0.693 unlabeled 0.67 1.5
#> 10506 0.58 0.514 -0.69 0.97 -1.2 -0.122 unlabeled 1.53 -2.7Conclusions
The ipd package offers a suite of functions for
conducting inference on predicted data. With custom methods for
printing, summarizing, tidying, glancing, and augmenting model outputs,
ipd streamlines the process of IPD-based inference in
R. We will continue to develop this package to include more
targets of inference and IPD methods as they are developed, as well as
additional functionality for analyzing such data. For further
information and detailed documentation, please refer to the function
help pages within the package, e.g.,
?ipdFeedback
For questions, comments, or any other feedback, please contact the developers (ssalerno@fredhutch.org).
Contributing
Contributions are welcome! Please open an issue or submit a pull request on GitHub.
Session Info
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] caret_7.0-1 lattice_0.22-7 patchwork_1.3.2 lubridate_1.9.5
#> [5] forcats_1.0.1 stringr_1.6.0 dplyr_1.2.0 purrr_1.2.1
#> [9] readr_2.2.0 tidyr_1.3.2 tibble_3.3.1 ggplot2_4.0.2
#> [13] tidyverse_2.0.0 ipd_0.4.1.9000 BiocStyle_2.38.0
#>
#> loaded via a namespace (and not attached):
#> [1] tidyselect_1.2.1 timeDate_4052.112 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 pROC_1.19.0.1
#> [7] digest_0.6.39 rpart_4.1.24 timechange_0.4.0
#> [10] lifecycle_1.0.5 survival_3.8-3 magrittr_2.0.4
#> [13] compiler_4.5.2 rlang_1.1.7 sass_0.4.10
#> [16] tools_4.5.2 utf8_1.2.6 yaml_2.3.12
#> [19] data.table_1.18.2.1 knitr_1.51 labeling_0.4.3
#> [22] plyr_1.8.9 RColorBrewer_1.1-3 withr_3.0.2
#> [25] desc_1.4.3 nnet_7.3-20 grid_4.5.2
#> [28] stats4_4.5.2 e1071_1.7-17 future_1.69.0
#> [31] globals_0.19.0 scales_1.4.0 iterators_1.0.14
#> [34] MASS_7.3-65 cli_3.6.5 rmarkdown_2.30
#> [37] ragg_1.5.1 generics_0.1.4 future.apply_1.20.2
#> [40] tzdb_0.5.0 reshape2_1.4.5 proxy_0.4-29
#> [43] cachem_1.1.0 splines_4.5.2 parallel_4.5.2
#> [46] BiocManager_1.30.27 vctrs_0.7.1 hardhat_1.4.2
#> [49] Matrix_1.7-4 jsonlite_2.0.0 bookdown_0.46
#> [52] hms_1.1.4 listenv_0.10.1 systemfonts_1.3.2
#> [55] foreach_1.5.2 gam_1.22-7 gower_1.0.2
#> [58] jquerylib_0.1.4 recipes_1.3.1 glue_1.8.0
#> [61] parallelly_1.46.1 pkgdown_2.2.0 codetools_0.2-20
#> [64] stringi_1.8.7 gtable_0.3.6 pillar_1.11.1
#> [67] htmltools_0.5.9 ipred_0.9-15 randomForest_4.7-1.2
#> [70] lava_1.8.2 R6_2.6.1 textshaping_1.0.5
#> [73] evaluate_1.0.5 bslib_0.10.0 class_7.3-23
#> [76] Rcpp_1.1.1 nlme_3.1-168 prodlim_2025.04.28
#> [79] mgcv_1.9-3 ranger_0.18.0 xfun_0.56
#> [82] fs_1.6.7 pkgconfig_2.0.3 ModelMetrics_1.2.2.2